The software development sometimes implies changes that affect the data model but such modifications have a series of problems such as the necessity of doing them online or the size of data to be reorganized.
In this post I want to talk about the existing tools for database schema change in MySQL ecosystem, what limitations do those tools have if you use Galera Cluster for replication and how I have adapted gh-ost, the GitHub schema change tool, to be able to use it with Galera.
Schema changes
With MySQL it is possible to make schema changes in two main ways:
- Using the
ALTERoperation of MySQL; it is the simplest way but it does not allow to pause the process in case of necessity and except for certain operations, it prevents the concurrent use of the table to be modified during the process. - Through the use of third party tools that allow a greater control of the process although with certain restrictions. Some of these tools can be pt-osc, OnlineSchemaChange or gh-ost.
These two methods are also applicable if you use Galera although, because it follows a master-master approach, it has some peculiarities to apply database changes, both through the operations provided by MySQL and by the third party tools.
Galera
Galera is a plug-in for InnoDB that provides a multi-master virtually synchronous replication. This approach allows, unlike normal MySQL asynchronous replication, that all the nodes in the cluster have the same data and, therefore, do writes in any node of the cluster sacrificing some write performance.
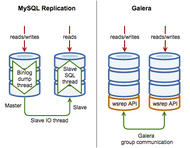
Schema changes are special operations in Galera, since they modify the database and are non-transactional. Galera has two modes for applying database changes using the ALTER operation:
- TOI1 are schema changes made in all nodes of the cluster in the same total order sequence, preventing other transactions from being applied during the operation.
- RSU2 are schema changes that are executed locally, affecting only the node in which they are executed. The changes are not replicated to the rest of the cluster.
These two modes have a number of drawbacks: the TOI operations prevent other transactions to commit in the whole cluster during the schema change while the RSU operations can leave the cluster in an inconsistent state if the binary log in ROW format is not compatible between schemas.
Regarding the use of third party tools, Galera has a series of limitations among which is the lack of support for table locking, an operation necessary in OnlineSchemaChange and gh-ost tools to apply the last events due to its asynchronous nature, a problem that pt-osc does not have because the events are applied by the database due to the use of triggers.
Although pt-osc is compatible with Galera, the use of triggers presents a number of drawbacks because it is not possible to pause the operation completely if necessary and the use of triggers adds an extra load to the database. Therefore, to allow the use of gh-ost in Galera, it is necessary to investigate why it need the use of LOCK TABLES and look for an alternative approach.
gh-ost
gh-ost is GitHub's tool for applying online schema changes and has interesting advantages over other existing tools. One of its main features is that it doesn't use triggers to synchronize the changes of the original table with the ghost table 3 but the binlogs of MySQL and therefore it really allows to stop the migration completely if necessary.

The reason that prevents using gh-ost with Galera is that, in order to do the cut-over phase, gh-ost makes use of the lock operation, that it is not supported in Galera.
Cut-over
In the documentation of gh-ost the cut-over phase is defined as the final major step of the migration and its goal is to replace the ghost table with the original one. For this purpose, it is necessary that both tables have the same records applied at the time of the swap, otherwise data would be lost in the migration process.
Unlike other online schema change tools such as pt-osc, gh-ost does not delegate in the database the application of the modified records during the migration and, therefore, it needs to momentarily block the writes in the original table until all pending changes in the binlog are applied, that is where the use of the lock operation in the original table is necessary.
LOCK TABLES
The first approach that may come to mind is that although the lock operation in Galera does not allow blocking access to a table in all nodes atomically, it does accept blocking access to a particular node, so it may be possible to apply LOCK TABLES manually in all nodes. After some research and a couple of tests this approach is discarded for several reasons:
- The atomic cut-over algorithm of
gh-ostneeds the use of several independent connections to work and although it guarantees to leave the cluster in a consistent state in the case of errors in the connections, this premise is no longer true if aLOCK TABLESmust be applied for each node. If you want to know howgh-oststrategy to apply the atomic cut-over works, I recommend you to read Issue #82. - As can be seen in MDEV-12647, it is quite possible to leave some of the nodes hanging when using the
LOCK TABLESon each node.
Therefore, the use of LOCK TABLES is discarded and it is necessary to analyze other existing solutions to perform schema migrations without loss of service and that if they allow its use with the Galera, that is where pt-osc comes into play.

pt-osc
pt-osc is a Percona tool that allows to perform schema migrations without loss of service compatible with Galera and it is based on delegating to the database the data modified during the migration using triggers, so the changes of the original table are synchronized with the ghost table. If you want to know how to ensure consistency I recommend you to read this answer from StackExchange.

Solution proposed
Therefore, if it is possible to perform a consistent migration using triggers it may be possible to use them even if only for the cut-over phase. To do this, it is possible to raise a new cut-over strategy, the procedure for which is as follows:
- At the time of starting the cut-over an event is injected in the binlog to notify
gh-ostto stop writing the new records in the ghost table but to keep reading them from the binlog. - Once the
gh-ostevent is received it stops applying the events but stores the values according to the unique key used during the migration. - The necessary triggers are created to synchronize the new records between the original table and the ghost one.
- A new event is injected into the binlog to notify that the triggers have been created.
- Once this second event is received, the binlog is no longer read and therefore alto it stop storage the values according to the unique key.
- The records between the two events may be inconsistent since some recors of the binlog have not been applied. To solve this problem, a clean-up phase is performed, which consists of removing them from the ghost table is exists and inserting them again from the original table.
- Once the events have been sanitized, both tables are consistent, so it is possible to use the
RENAME TABLEoperation to swap the original table with the ghost one in an atomic way. - After that operation or in the case of failure, the triggers are removed.
Results and conclusion
Once I proposed a solution I implemented the necessary changes to the gh-ost code and after a couple of weeks of testing we started using it in production with very good results, so I created the pull request #780.
Regarding the conclusion, even if gh-ost is considered triggerless, the life of the necessary triggers will be equal to the time it takes to apply the pending changes to the binlog and clean up the entries that may be inconsistent, which will be just a few seconds in the worst case, so it is considered acceptable.